✨ [2025-05-30] 添加 oss 使用说明
All checks were successful
Publish to Confluence / confluence (push) Successful in 1m7s
All checks were successful
Publish to Confluence / confluence (push) Successful in 1m7s
This commit is contained in:
parent
eaea981ace
commit
e3703d69f3
@ -100,4 +100,4 @@ yuanmeng:
|
||||
#- 读取超时时间
|
||||
read-timeout: 60
|
||||
read-time-unit: seconds
|
||||
```
|
||||
```
|
||||
|
||||
146
文档/基础组件/oss/20250530-engine-starter-oss-2.0.0.md
Normal file
146
文档/基础组件/oss/20250530-engine-starter-oss-2.0.0.md
Normal file
@ -0,0 +1,146 @@
|
||||
<!-- Space: qifu -->
|
||||
<!-- Parent: 后端技术&知识&规范 -->
|
||||
<!-- Parent: 技术方案 -->
|
||||
<!-- Parent: 基建 -->
|
||||
<!-- Parent: 00-基础组件 -->
|
||||
<!-- Parent: 00-EngineStarterOss使用指南 -->
|
||||
<!-- Title: 20250509-engine-starter-oss-2.0.0 -->
|
||||
|
||||
<!-- Macro: :anchor\((.*)\):
|
||||
Template: ac:anchor
|
||||
Anchor: ${1} -->
|
||||
<!-- Macro: \!\[.*\]\((.+)\)\<\!\-\- width=(.*) \-\-\>
|
||||
Template: ac:image
|
||||
Url: ${1}
|
||||
Width: ${2} -->
|
||||
<!-- Macro: \<\!\-\- :toc: \-\-\>
|
||||
Template: ac:toc
|
||||
Printable: 'false'
|
||||
MinLevel: 2
|
||||
MaxLevel: 4 -->
|
||||
<!-- Include: 杂项/声明文件.md -->
|
||||
|
||||
<!-- :toc: -->
|
||||
|
||||
# engine-starter-oss 使用教程
|
||||
|
||||
> 这是一个基于 `aws-s3-client` 封装的 oss 存储对接项目
|
||||
|
||||
## 特性
|
||||
|
||||
- [X] `YmOssTemplateContext` 消息发送工具类
|
||||
|
||||
## 快速开始
|
||||
|
||||
- **注意:** `qifu-saas-parent >= 2.0.0-SNAPSHOT`
|
||||
|
||||
### 添加依赖
|
||||
|
||||
```xml
|
||||
|
||||
<dependency>
|
||||
<groupId>com.yuanmeng.engine</groupId>
|
||||
<artifactId>engine-starter-oss</artifactId>
|
||||
<version>2.0.0-SNAPSHOT</version>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
### 配置 OSS
|
||||
|
||||
```yaml
|
||||
yuanmeng:
|
||||
oss:
|
||||
#- 阿里云
|
||||
endpoint: https://oss-cn-shenzhen.aliyuncs.com
|
||||
region: cn-shenzhen
|
||||
access-key: xxx
|
||||
secret-key: xxx
|
||||
bucket-name: xxx
|
||||
path-style-access: false
|
||||
configs:
|
||||
#- minio
|
||||
minIoOssTemplate:
|
||||
endpoint: http://local.com:9000
|
||||
region: cn-shenzhen
|
||||
access-key: xxx
|
||||
secret-key: xxx
|
||||
bucket-name: aws-s3-client
|
||||
path-style-access: true
|
||||
```
|
||||
|
||||
## 工具使用
|
||||
|
||||
### 文件存储使用
|
||||
|
||||
```java
|
||||
|
||||
@Slf4j
|
||||
@RestController
|
||||
@RequiredArgsConstructor
|
||||
@RequestMapping("/oss")
|
||||
public class TestController {
|
||||
|
||||
@PostMapping("/upload")
|
||||
public String upload(MultipartFile file,
|
||||
@RequestParam(value = "client", required = false) String client) throws IOException {
|
||||
log.info(YmThreadLocalUtils.getTokenInfoString());
|
||||
PutObjectResponse local = YmOssTemplateContext.load(client)
|
||||
.putObject(file.getOriginalFilename(), file.getInputStream());
|
||||
return local.toString();
|
||||
}
|
||||
|
||||
@GetMapping("/url-get")
|
||||
public String getUrl(@RequestParam("name") String objectName,
|
||||
@RequestParam(value = "client", required = false) String client) {
|
||||
log.info(YmThreadLocalUtils.getTokenInfoString());
|
||||
return YmOssTemplateContext.load(client).getObjectURL(objectName);
|
||||
}
|
||||
|
||||
@GetMapping("/url-get-presigned")
|
||||
public String getPresignedUrl(@RequestParam("name") String objectName,
|
||||
@RequestParam(value = "client", required = false) String client) {
|
||||
log.info(YmThreadLocalUtils.getTokenInfoString());
|
||||
return YmOssTemplateContext.load(client).getPresignedURL(objectName, 10);
|
||||
}
|
||||
|
||||
@GetMapping("/url-post-presigned")
|
||||
public String getPostPresignedUrl(@RequestParam("name") String objectName,
|
||||
@RequestParam(value = "client", required = false) String client) {
|
||||
log.info(YmThreadLocalUtils.getTokenInfoString());
|
||||
return YmOssTemplateContext.load(client).getPutPresignedURL(objectName, 10);
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
## 完整配置
|
||||
|
||||
```yaml
|
||||
yuanmeng:
|
||||
oss:
|
||||
#- 阿里云
|
||||
endpoint: https://oss-cn-shenzhen.aliyuncs.com
|
||||
region: cn-shenzhen
|
||||
access-key: xxx
|
||||
secret-key: xxx
|
||||
bucket-name: xxx
|
||||
path-style-access: false
|
||||
configs:
|
||||
#- minio
|
||||
minIoOssTemplate:
|
||||
endpoint: http://local.com:9000
|
||||
region: cn-shenzhen
|
||||
access-key: xxx
|
||||
secret-key: xxx
|
||||
bucket-name: aws-s3-client
|
||||
path-style-access: true
|
||||
#- qiniu
|
||||
qiNiuOssTemplate:
|
||||
endpoint: xxx
|
||||
region: cn-shenzhen
|
||||
access-key: xxx
|
||||
secret-key: xxx
|
||||
bucket-name: aws-s3-client
|
||||
path-style-access: true
|
||||
#- 其他支持 s3 协议的 oss 存储
|
||||
```
|
||||
@ -3,8 +3,8 @@
|
||||
<!-- Parent: 技术方案 -->
|
||||
<!-- Parent: 基建 -->
|
||||
<!-- Parent: 00-基础组件 -->
|
||||
<!-- Parent: 00-EngineStarterFeign使用指南 -->
|
||||
<!-- Title: 20250509-engine-starter-feign-2.0.0 -->
|
||||
<!-- Parent: 00-EngineStarterRocketmq使用指南 -->
|
||||
<!-- Title: 20250529-engine-starter-rocketmq-2.0.0 -->
|
||||
|
||||
<!-- Macro: :anchor\((.*)\):
|
||||
Template: ac:anchor
|
||||
|
||||
106
方案/20250530-私有化部署推理大模型调研.md
Normal file
106
方案/20250530-私有化部署推理大模型调研.md
Normal file
@ -0,0 +1,106 @@
|
||||
# 私有化部署推理大模型调用
|
||||
|
||||
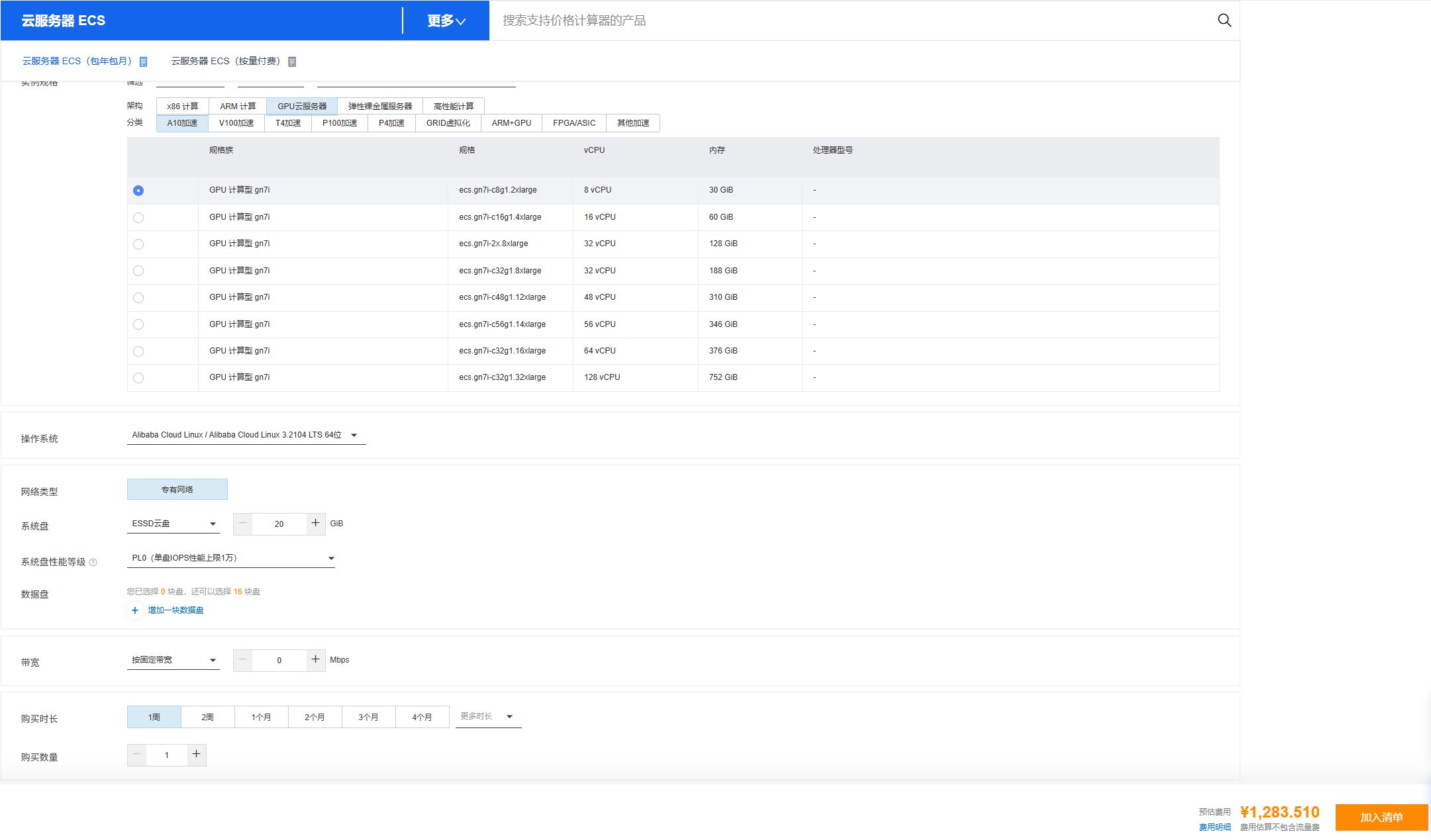
## 阿里云GPU服务器部署
|
||||
- 
|
||||
|
||||
----
|
||||
|
||||
## 本地化部署
|
||||
|
||||
基于 DeepSeek-R1-32B 模型为 30 人团队部署本地化代码生成服务。
|
||||
|
||||
---
|
||||
|
||||
### **核心硬件需求分析**
|
||||
1. **模型特性**
|
||||
- DeepSeek-R1-32B:320亿参数的大模型,需高显存支持(FP16 需 64GB+,实际部署需量化)。
|
||||
- 推荐量化方案:**4-bit GPTQ/AWQ**(显存占用降至 20-25GB,性能损失<5%)。
|
||||
|
||||
2. **并发与响应时间**
|
||||
- 30人团队日均请求量:约 300-600 次(按每人每日 10-20 次估算)。
|
||||
- 高峰并发:约 10-15 个并发请求。
|
||||
- 可接受延迟:**<5秒/请求**(生成 200-500 tokens)。
|
||||
|
||||
3. **关键硬件瓶颈**
|
||||
- **显存容量**:加载量化模型需 ≥24GB/卡,推荐 ≥48GB。
|
||||
- **GPU 算力**:高吞吐需强 FP16/INT4 算力。
|
||||
- **内存与网络**:数据预处理、多卡通信需大内存和高速互联。
|
||||
|
||||
---
|
||||
|
||||
### **推荐硬件配置方案**
|
||||
#### **方案 1:高性价比(双卡推理)**
|
||||
| **组件** | **型号与规格** | **数量** | **用途说明** |
|
||||
|----------------|---------------------------|----------|---------------------------|
|
||||
| **GPU** | NVIDIA RTX 6000 Ada (48GB) | 2 | 4-bit 量化模型并行推理 |
|
||||
| **CPU** | AMD EPYC 7302P (16核) | 1 | 任务调度/数据预处理 |
|
||||
| **内存** | DDR4 ECC 256GB | 1套 | 支持大规模批量处理 |
|
||||
| **SSD** | NVMe U.2 3.84TB | 2 | 模型存储+日志(RAID 1) |
|
||||
| **网络** | 10GbE 双端口网卡 | 1 | 内网高速通信 |
|
||||
| **电源** | 1600W 80+铂金 | 1 | 支撑双卡满负载 |
|
||||
| **机箱** | 4U 塔式/机架式 | 1 | 扩展性与散热 |
|
||||
|
||||
#### **方案 2:高性能(企业级多卡)**
|
||||
| **组件** | **型号与规格** | **数量** | **用途说明** |
|
||||
|----------------|---------------------------|----------|---------------------------|
|
||||
| **GPU** | NVIDIA L40S (48GB) | 2-3 | 专为AI优化,显存带宽更高 |
|
||||
| **CPU** | Intel Xeon Gold 6330 (28核)| 1 | 高并发预处理 |
|
||||
| **内存** | DDR4 ECC 512GB | 1套 | 支持更大批量 |
|
||||
| **SSD** | NVMe U.2 7.68TB | 2 | 高速存储冗余 |
|
||||
| **网络** | 25GbE 双端口 | 1 | 低延迟通信 |
|
||||
| **电源** | 2000W 冗余电源 | 2 | 企业级稳定性 |
|
||||
| **散热** | 专业风冷/水冷 | 1套 | 保障长时间满负载运行 |
|
||||
|
||||
> ✅ **关键选择逻辑**:
|
||||
> - **RTX 6000 Ada**:性价比高,48GB显存完美适配4-bit量化模型。
|
||||
> - **L40S**:企业级可靠性,适合7x24小时服务,但成本更高。
|
||||
> - **单卡 vs 多卡**:双卡可通过 Tensor Parallelism 提升吞吐量 1.8 倍,优化并发体验。
|
||||
|
||||
---
|
||||
|
||||
### **性能预估(基于方案1)**
|
||||
| **指标** | **性能值** |
|
||||
|------------------|-------------------------------|
|
||||
| 单请求延迟 | 3-4秒 (生成300 tokens) |
|
||||
| 峰值吞吐量 | 15-18 请求/秒 |
|
||||
| 支持最大上下文 | 128K tokens(需显存优化) |
|
||||
| 日均处理能力 | ≥1.2万次请求 |
|
||||
|
||||
---
|
||||
|
||||
### **软件栈优化建议**
|
||||
1. **推理框架**:
|
||||
- **vLLM**(高吞吐量)或 **TGI**(Hugging Face 优化版)。
|
||||
2. **量化部署**:
|
||||
- 使用 **AutoGPTQ** 或 **AWQ** 压缩模型至 4-bit。
|
||||
3. **API服务**:
|
||||
- FastAPI + Websocket,支持流式响应。
|
||||
4. **监控**:
|
||||
- Prometheus + Grafana 实时追踪 GPU 利用率/延迟。
|
||||
|
||||
---
|
||||
|
||||
### **预算估算(人民币)**
|
||||
| **类别** | **方案1(双卡)** | **方案2(三卡)** |
|
||||
|------------------|-----------------|-----------------|
|
||||
| 硬件采购 | 18万-22万 | 32万-38万 |
|
||||
| 部署与调优 | 3万-5万 | 5万-8万 |
|
||||
| 第一年运维 | 2万-3万 | 4万-6万 |
|
||||
| **总计(首年)** | **23万-30万** | **41万-52万** |
|
||||
|
||||
> 💡 **成本细节**:
|
||||
> - GPU 成本占比 70%(RTX 6000 Ada 单价约 6万,L40S 约 8万)。
|
||||
> - 运维含电费(满载约 1.5万/年)、备用配件、系统更新。
|
||||
|
||||
---
|
||||
|
||||
### **实施建议**
|
||||
1. **分阶段部署**:
|
||||
- 先用单卡测试实际负载,再扩展至双卡。
|
||||
2. **灾备设计**:
|
||||
- 配置云服务器冷备(如 AWS g5.48xlarge),应对硬件故障。
|
||||
3. **安全策略**:
|
||||
- 私有化部署需设置 VPN 访问 + API 密钥认证。
|
||||
|
||||
> ✨ **最终推荐**:
|
||||
> **选择方案1(双 RTX 6000 Ada)**,在预算 25 万左右实现高效服务,平衡性能与成本,完全满足 30 人团队需求。
|
||||
Loading…
x
Reference in New Issue
Block a user